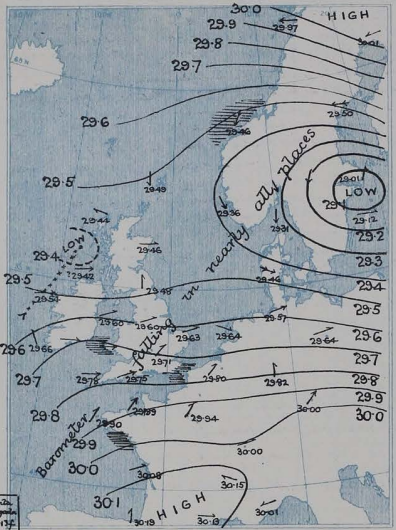
Data from EMULATE¶
As part of the work to make the EMULATE mean-sea-level pressure dataset, some observations from the Daily Weather Reports were (commercially) transcribed in the early 2000’s. This transcription project covered the period 1856-1881, but only transcribed part of the observations: only pressure and pressure tendencies were transcribed, and only from selected stations. These data were not actually used in EMULATE, and this is the first time they have been released.
The transcriptions were collected into spreadsheet files:
"DAILY WEATHER REPORTS (1861-1881)",,,,,,,,,,,,,,,
,,,,,,,,,,,,,,,
1861,January,February,March,April,May,June,July,August,September,October,November,December,,,
,,,,,,,,,,,,,,,
1,29.59,29.73,29.25,29.94,30.16,29.75,30.03,29.82,-9999,29.51,29.3,-9999,"1 August 1861 - The first ""forecast"" for the general public Reputedly Robert Fitzroy coined the word ""forecast"".",,
2,30.23,30.37,29.54,29.92,30.35,-9999,29.73,29.73,29.71,29.64,29.35,30.28,"The first storm warning had been issued in February 1861.",,
3,30.33,-9999,-9999,29.86,29.99,30.1,-9999,29.32,29.49,30.12,-9999,29.99,,,
4,30.21,29.24,29.67,29.85,30.3,30.09,-9999,-9999,29.53,30.22,29.61,30,,,
5,30.15,29.35,29.76,29.9,-9999,30.04,-9999,29.53,29.83,29.91,29.35,29.55,,,
6,-9999,20.04,28.99,30.16,30.13,30.18,29.37,29.65,29.53,-9999,29.38,29.56,,,
7,30.19,28.92,29.71,-9999,30.08,30.13,-9999,29.72,29.63,29.96,29.19,28.99,,,
8,-9999,29.69,29.5,30.48,29.92,30.04,29.73,29.27,-9999,29.65,29.41,-9999,,,
9,29.99,30.12,30.012,30.53,29.61,-9999,29.77,29.6,29.75,29.68,29.51,29.44,,,
10,30.27,-9999,-9999,30.29,29.81,29.79,29.68,29.87,29.93,29.95,-9999,29.65,,,
11,30.05,30.27,28.92,30.36,29.89,29.84,29.59,-9999,29.93,29.33,29.11,29.65,,,
12,29.69,29.75,29.11,30.5,-9999,29.73,29.58,29.45,29.98,29.39,29.46,29.36,,,
13,-9999,29.62,29.81,30.39,30.16,30.09,29.78,29.71,29.78,-9999,29.71,29.19,,,
14,29.06,29.89,29.93,-9999,30.31,30.25,-9999,29.98,29.15,29.79,29.41,29.47,,,
15,30.31,29.54,29.62,30.43,30.25,30.25,29.68,29.48,-9999,30.18,29.51,-9999,,,
16,30.39,29.44,29.56,30.44,30.14,-9999,29.53,29.62,29.9,30.29,29.75,30.11,,,
17,30.39,-9999,-9999,30.42,30.19,30.19,29.58,29.71,30.08,30.33,-9999,29.98,,,
18,30.21,29.69,28.8,30.26,30.3,30.14,29.33,-9999,30.1,30.22,30.22,30.06,,,
19,30.01,29.6,28.79,30.32,-9999,30.1,29.38,29.54,30.08,29.93,29.89,30.5,,,
20,-9999,29.46,29.34,30.23,30.24,29.94,29.53,29.63,29.61,-9999,29.77,30.46,,,
21,30.09,28.97,28.87,-9999,30.17,29.96,-9999,29.99,29.66,29.84,29.41,30.36,,,
22,30.16,29.01,29.35,29.86,30.06,29.94,29.58,30.07,-9999,29.81,29.08,-9999,,,
23,29.99,29.52,29.36,29.85,29.88,-9999,29.33,29.73,28.93,29.87,29.25,30.48,,,
24,29.69,-9999,-9999,29.91,29.84,29.65,29.63,29.64,29.09,29.79,-9999,30.43,,,
25,29.43,30.31,29.7,29.79,29.42,29.69,29.33,-9999,29.37,30.1,29.09,-9999,,,
26,29.79,30.03,29.45,30.06,-9999,29.63,29.5,29.99,29.61,30.38,29.14,30.32,,,
27,-9999,29.72,29.43,30.19,29.81,29.78,29.58,30.02,29.83,-9999,29.47,30.59,,,
28,29.95,29.49,29.45,-9999,30.14,29.78,-9999,29.88,29.53,30.36,29.66,30.54,,,
29,29.97,,29.51,30.12,29.92,29.67,29.83,29.63,-9999,30.2,29.35,-9999,,,
30,29.82,,29.45,30.15,29.88,,29.43,29.68,29.95,29.94,29.32,30.56,,,
31,29.76,,,,29.93,,29.6,30.12,,29.63,,30.41,,,
,,,,,,,,,,,,,,,
One complication with the DWR is that exact observation locations are not given, only approximate locations (e.g. ‘Aberdeen’). For MSLP, observations exact locations are not vital, so a nominal location has been assigned for each station.
To make the data easily useable, the station files have been converted into the same monthly data format used for weatherrescue.org data; assigning latitudes, longitudes, and times in the process.
#!/usr/bin/env python
# Convert the digitised data from Rob's Emulate files to the format
# Ed Hawkins is using.
import os
import os.path
import pandas
import numpy
import datetime
import calendar
import sys
import re
# Get script directory
sd=os.path.dirname(os.path.abspath(__file__))
# Load the Station names and locations
md=pandas.read_csv("%s/../../Lisa_storms/metadata/names.csv" % sd,
header=None)
# Get station name from file name
def get_station_name(file_name):
sn=os.path.basename(file_name).split('.')
if sn[0]=='DWR_stations':
return sn[1].upper()
return sn[0].upper()
# The old Emulate data is in several different formats.
# These files are in one-ob-per-day format
Files_opd=(
'Alexandria.Alexandria.csv',
'DWR_stations.Aberdeen.csv',
'DWR_stations.Algiers.csv',
'DWR_stations.Angra.csv',
'DWR_stations.Biskra.csv',
'DWR_stations.Brest.csv',
'DWR_stations.Funchal.csv',
'DWR_stations.Galway.csv',
'DWR_stations.Greencastle.csv', # Changes to TPD in 1868
'DWR_stations.Holyhead.csv',
'DWR_stations.La Coruna.csv',
'DWR_stations.Liverpool.csv',
'DWR_stations.Mogador.csv',
'DWR_stations.Nairn.csv', # Changes from TPD in 1871
'DWR_stations.Pembroke.csv',
'DWR_stations.Plymouth.csv',
'DWR_stations.Portsmouth.csv',
'DWR_stations.Rochefort.csv', # Changes to TPD in 1871
'DWR_stations.Roches Pt.csv',
'DWR_stations.Scilly Islands.csv',
'DWR_stations.Toulon.csv',
'DWR_stations.Valentia.csv',
'Lesina_Split.Sheet1.csv',
'Lisbon.Lisbon.csv',
'Lyons.Lyons.csv',
'Rome.Rome.csv',
'Sibiu.Funchal.csv',
'Stornaway.Stornaway.csv',
)
# These files are in two-ob-per-day format
Files_tpd=(
'DWR_stations.Nairn.csv', # Changes to OPD in 1871
'DWR_stations.Penzance.csv',
'DWR_stations.Scarborough.csv',
'DWR_stations.Greencastle.csv', # Changes from OPD in 1868
'DWR_stations.Rochefort.csv', # Changes from OPD in 1871
)
def load_from_file_opd(file_name):
station=get_station_name(file_name)
csv=pandas.read_csv(file_name,header=None)
Hours={
'Lyons': 9,
'Alexandria': 9,
'Sibu': 8,
'Stornoway': 9,
'Brest': 8, # Change to 18 previous day on 1875-04-01
'Rochefort': 8,
'Mogador': 7,
'Biskra': 7,
}
# Hour (gmt) of the daily ob.
def obs_hour(station,year,month):
if station=='Brest':
if year>1875 or (year==1875 and month>3):
return -6
return Hours.get(station,8)
# Find the index numbers starting the data for a year
# (Lines with 'January' in the second column)
def find_year_starts(tab):
return tab[tab.iloc[:,1].str.contains('January',na=False)].index.values
# Extract a year's worth of data given the start location
def get_data_for_year(station,tab,istart):
dates=[]
pressures=[]
year=int(tab.iloc[istart,0])
for month in range(1,13):
hour=obs_hour(station,year,month)
lastday=calendar.monthrange(year,month)[1]
for day in range(1,lastday+1):
pre=tab.iloc[istart+day+1,month]
try:
pre=float(pre)
if numpy.isnan(pre): continue
if pre<0: continue # -9999 - missing
if pre<35: pre=pre*33.8639 # InHg
if pre<800: pre=pre*1.33 # mmHg
except ValueError:
continue
dates.append(datetime.datetime(year,month,day,0)+
datetime.timedelta(hours=hour))
pressures.append(pre)
return {'dates':dates,'pressures':pressures}
year_i=find_year_starts(csv)
file_data={}
for idx in year_i:
year=int(csv.iloc[idx,0])
file_data["%04d" % year]=get_data_for_year(station,csv,idx)
return file_data
def load_from_file_tpd(file_name):
station=get_station_name(file_name)
csv=pandas.read_csv(file_name,header=None)
# Find the index numbers starting the data for a year
# (Lines with 'January' in the third column)
def find_year_starts(tab):
return tab[tab.iloc[:,2].str.contains('January',na=False)].index.values
# Convert '2pm' into 14'
def hour_from_string(hrst):
try:
hour=int(re.findall('[0-9]+', hrst)[0])
except IndexError:
return None
if len(re.findall('pm', hrst.lower())) !=0:
hour=hour+12
if hour==24: hour=12
return hour
# Extract a year's worth of data given the start location
def get_data_for_year(station,tab,istart):
dates=[]
pressures=[]
year=int(tab.iloc[istart,0])
for month in range(1,13):
lastday=calendar.monthrange(year,month)[1]
for day in range(1,lastday+1):
for hri in (0,1):
if hri==0:
pre=tab.iloc[istart+day*2,month+1]
else:
pre=tab.iloc[istart+day*2+1,month+1]
try:
pre=float(pre)
if numpy.isnan(pre): continue
if pre<0: continue # -9999 - missing
if pre<35: pre=pre*33.8639 # InHg
if pre<800: pre=pre*1.33 # mmHg
except ValueError:
continue
if hri==0:
hour=hour_from_string(tab.iloc[istart+day*2,1])
if hour is None: continue
dates.append(datetime.datetime(year,month,day,hour))
else:
hour=hour_from_string(tab.iloc[istart+day*2+1,1])
if hour is None: continue
dates.append(datetime.datetime(year,month,day,hour))
pressures.append(pre)
return {'dates':dates,'pressures':pressures}
year_i=find_year_starts(csv)
file_data={}
for idx in year_i:
year=int(csv.iloc[idx,0])
file_data["%04d" % year]=get_data_for_year(station,csv,idx)
return file_data
# Specific functions for custom formats
def load_from_file_teneriffe(file_name):
csv=pandas.read_csv(file_name,header=None)
file_data={}
dc=csv[csv.iloc[:,0].str.contains('\d\d\d\d',na=False,regex=True)].index.values
for idx in dc:
try:
year = int(csv.iloc[idx,0])
month = int(csv.iloc[idx,1])
day = int(csv.iloc[idx,2])
hour = int(csv.iloc[idx,3])
minute = int(csv.iloc[idx,4])
except ValueError: continue # Missing date
try:
pre=float(csv.iloc[idx,5])
if numpy.isnan(pre): continue
if pre<0: continue # -9999 - missing
if pre<35: pre=pre*33.8639 # InHg
if pre<800: pre=pre*1.33 # mmHg
except ValueError: continue # Missing pressure
if "%04d" % year not in file_data:
file_data["%04d" % year]={}
if 'dates' not in file_data["%04d" % year]:
file_data["%04d" % year]['dates']=[]
file_data["%04d" % year]['pressures']=[]
file_data["%04d" % year]['dates'].append(
datetime.datetime(year,month,day,hour))
file_data["%04d" % year]['pressures'].append(pre)
return file_data
def load_from_file_middle_east(file_name,column):
csv=pandas.read_csv(file_name,header=None)
file_data={}
dc=csv[csv.iloc[:,0].str.contains('\d\d\d\d',na=False,regex=True)].index.values
for idx in dc:
try:
year = int(csv.iloc[idx,0])
month = int(csv.iloc[idx,1])
day = int(csv.iloc[idx,2])
hour = 8
minute = 0
except ValueError: continue # Missing date
try:
pre=float(csv.iloc[idx,column])
if numpy.isnan(pre): continue
if pre<0: continue # -9999 - missing
if pre<35: pre=pre*33.8639 # InHg
if pre<800: pre=pre*1.33 # mmHg
except ValueError: continue # Missing pressure
if "%04d" % year not in file_data:
file_data["%04d" % year]={}
if 'dates' not in file_data["%04d" % year]:
file_data["%04d" % year]['dates']=[]
file_data["%04d" % year]['pressures']=[]
file_data["%04d" % year]['dates'].append(
datetime.datetime(year,month,day,hour))
file_data["%04d" % year]['pressures'].append(pre)
return file_data
# Add a station's data to the output files
def output_station(name,sdata):
LastF=''
Of=None
opfile=None
mdl=md[md.iloc[:,0].str.lower()==name.lower()]
if mdl.empty:
raise Exception("No station %s in metadata" %
name)
for syr in list(sdata.keys()):
for idx in range(len(sdata[syr]['dates'])):
Of=("%s/../../data_from_Emulate/%04d/%02d/prmsl.txt" %
(sd,sdata[syr]['dates'][idx].year,
sdata[syr]['dates'][idx].month))
if Of!=LastF:
dn=os.path.dirname(Of)
if not os.path.isdir(dn):
os.makedirs(dn)
if opfile is not None:
opfile.close()
if os.path.getsize(LastF)==0:
os.remove(Of)
dn=os.path.dirname(LastF)
if not os.listdir(dn):
os.rmdir(dn)
opfile=open(Of, "a")
LastF=Of
opfile.write(("%04d %02d %02d %02d %02d %6.2f "+
"%7.2f %6.1f %16s\n") %
(sdata[syr]['dates'][idx].year,
sdata[syr]['dates'][idx].month,
sdata[syr]['dates'][idx].day,
sdata[syr]['dates'][idx].hour,
sdata[syr]['dates'][idx].minute,
mdl.iloc[0,2],mdl.iloc[0,3], #latlon
sdata[syr]['pressures'][idx], # ob value
mdl.iloc[0,1])) # name
if opfile is not None:
opfile.close()
# Load all the data
emulate_data={}
Files=os.listdir("%s/../original_data_csv" % sd)
if True:
for file_name in Files:
station_name=get_station_name(file_name)
# Once-per-day data
if file_name in Files_opd:
print(station_name)
if station_name not in emulate_data:
emulate_data[station_name]={}
emulate_data[station_name].update(load_from_file_opd(
"%s/../original_data_csv/%s" % (sd,file_name)))
# Twice_per_day data
if file_name in Files_tpd:
print(station_name)
if station_name not in emulate_data:
emulate_data[station_name]={}
emulate_data[station_name].update(load_from_file_tpd(
"%s/../original_data_csv/%s" % (sd,file_name)))
# Special cases
print('TENERIFE')
emulate_data['TENERIFE']=load_from_file_teneriffe(
"%s/../original_data_csv/Tenerife.Teneriffe.csv" % sd)
print('BAGHDAD')
emulate_data['BAGHDAD']=load_from_file_middle_east(
"%s/../original_data_csv/ME_daily_pressure.ME_daily_pressure.csv" % sd,3)
print('BASRA')
emulate_data['BASRA']=load_from_file_middle_east(
"%s/../original_data_csv/ME_daily_pressure.ME_daily_pressure.csv" % sd,4)
print('DIYARBAKIR')
emulate_data['DIYARBAKIR']=load_from_file_middle_east(
"%s/../original_data_csv/ME_daily_pressure.ME_daily_pressure.csv" % sd,5)
print('BEIRUT')
emulate_data['BEIRUT']=load_from_file_middle_east(
"%s/../original_data_csv/ME_daily_pressure.ME_daily_pressure.csv" % sd,6)
# Output the data in new format
for station in list(emulate_data.keys()):
output_station(station,emulate_data[station])